
在整个量化研究过程中,除了需要量化研究员具备编程和金融素养之外,还有一个十分重要,且不可或缺的部分——数据。
数据是一切分析的开端,本文将通过研报复现的方式,带着大家学习如何通过Python爬虫获取数据(内含代码)。


市值因子择时
在本文的最开始,将先简单阐明文章中所涉及到的研报内容。
文章中所用到的研报来自中信建投证券研究发展部发布的《因子深度研究系列:市值因子择时》。研报中主要针对小市值选股策略进行了优化(该策略曾在文章【前方高能】10年能赚70倍?量化选股带你躺着赚钱!中提及),其优化思路主要是根据不同的因子,对市值进行风格判断,找出适合何时适合小市值选股,何时适合大市值选股,以此进行风格轮动,避免单一的小市值选股在某些时段的巨大回撤。
优化思路
文中的市值因子择时策略主要如下:

注:本文将聚集因子的获取及构造过程,优化回测过程将于后续文章中讲解。
网络爬虫
数据的分析永远是从数据开始,根据优化思路,我们需首先确定所需数据,包括:
房地产开发投资完成额、CPI、PPI、沪深300、中证500、A股市场所有股票日线数据。
在1月上线的新课程《Python量化专题:金融数据、择时及选股策略》中为大家讲解了股票及指数数据的爬虫方法,因此,本文将以宏观数据为例,为大家简单讲解爬虫。

![]()
![]()
![]()
何为网络爬虫
网络爬虫,指自动提取网页内容的程序。从功能上去理解,就是能够通过编写爬虫脚本,获取网页上我们所浏览的内容。
因此,当我们决定通过网络爬虫的方法获取数据时,就和我们平时找数据的过程一样:先知道在哪能看到数据,编写爬虫脚本,利用程序下载数据。
那么,在哪能找到我们所需的宏观经济数据呢?![]()
找啊找啊找数据
本次策略过程中所用到的数据均可在东方财富网的「数据中心」中找到:
(具体数据来源可扫对应二维码查看)
房地产开发投资完成额
CPI
PPI
找到数据后,我们就可以进入到后续写代码等环节了~
才!怪!
你以为我们找数据的任务就结束了吗?

在正式进入写代码环节前,进行一步“抓包”,也就是找到真正存储数据的url(如图所示)
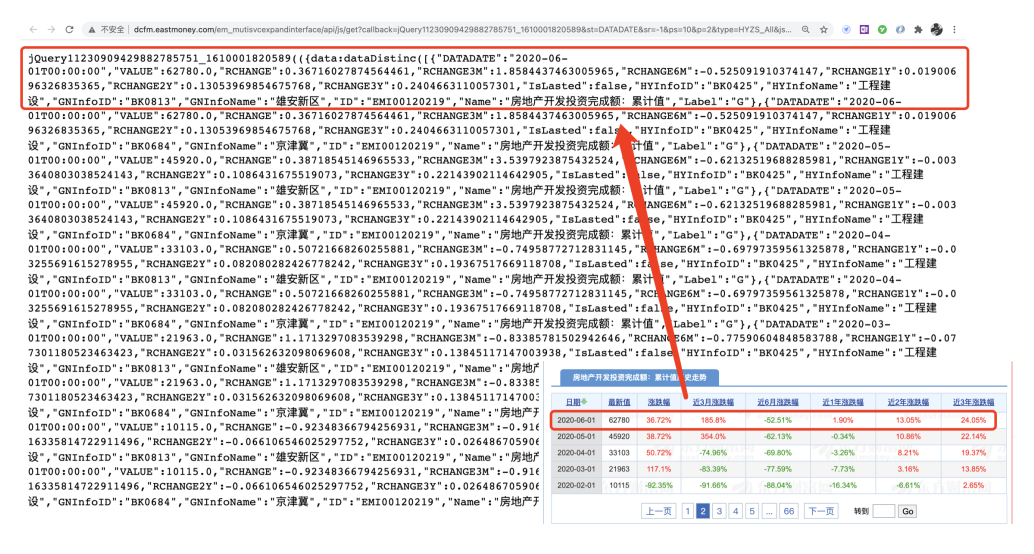
那么,如何找到这个神秘的url呢?
这里就需要用到Chrome浏览器的「开发者工具」这一爬虫神器 ,具体操作如下(以房地产开发投资完成额为例):
Step 1. 在当前网页
(http://data.eastmoney.com/cjsj/hyzs_list_EMI00120219.html)
下点击快捷键「F12」,打开开发者工具的network;
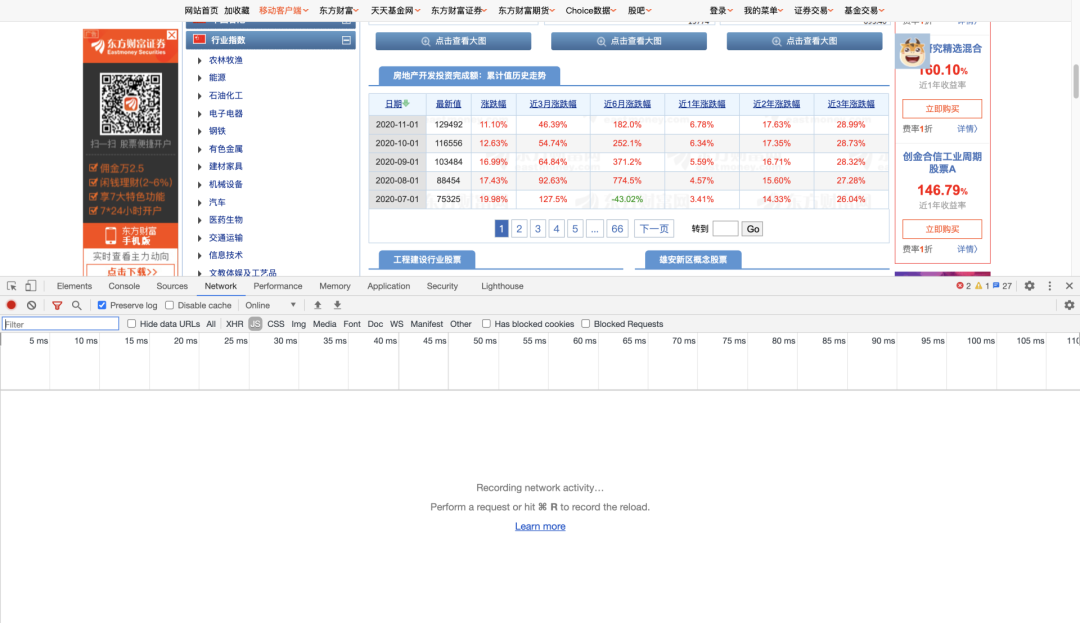
Step 2. 进行“抓包”。选中「JS」后,点击网页中不同页数,找到出现的js文件,观察其Preview内容是否与目标内容符合;
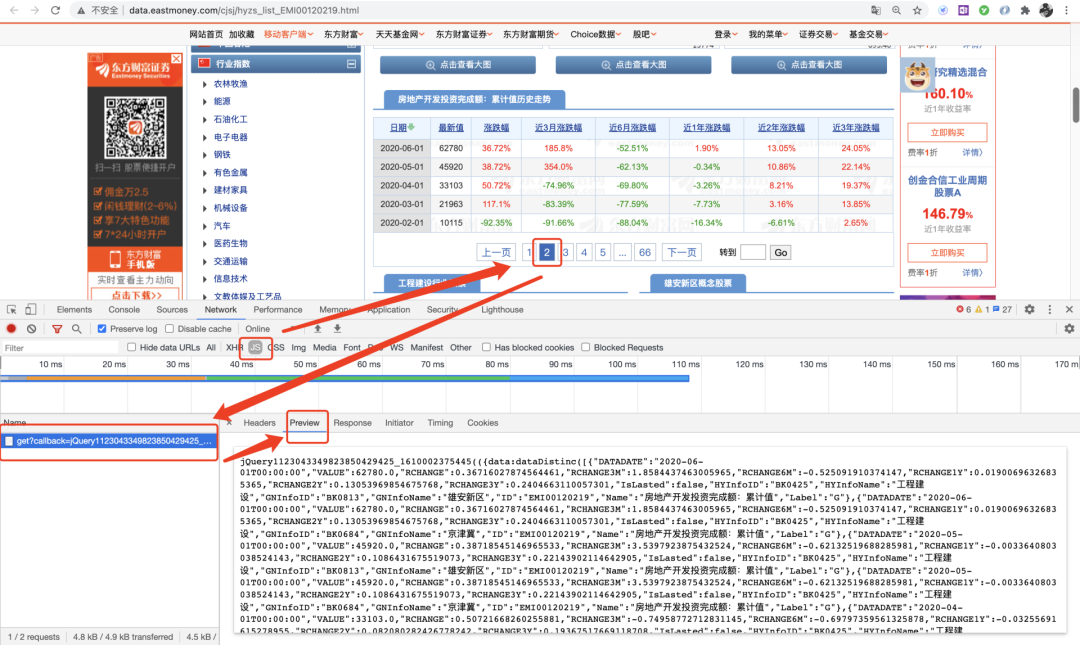
Step 3. 找到存储数据的js文件后,观察Headers内容,找到Request URL,解析其中参数。
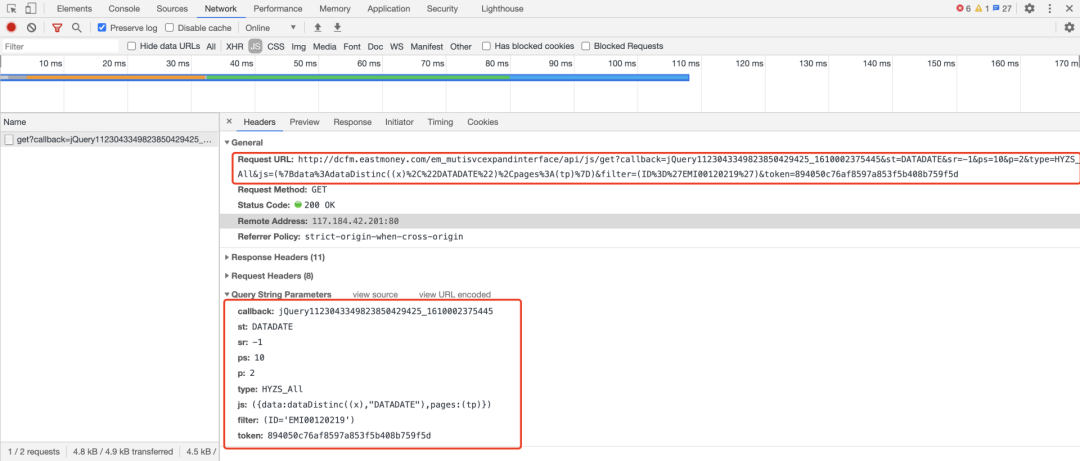
通过以上3步,我们便顺利找到了真正存储数据的网址,其实我们的爬虫大业已经完成了一大半,对其简单解析后将结果整理成代码:

10行代码搞定爬虫
接下来只需借助Requests模块,用2行代码(第6、7行)即可获取网页内容。

df返回值(部分)

如果需要获取更多的数据,将参数ps设置为甚至更高的数字去获取所有历史数据;或构造for循环去遍历不同页数(参数p)数据,以此获取所有数据。
本文中,小编采用的是第一种方法。
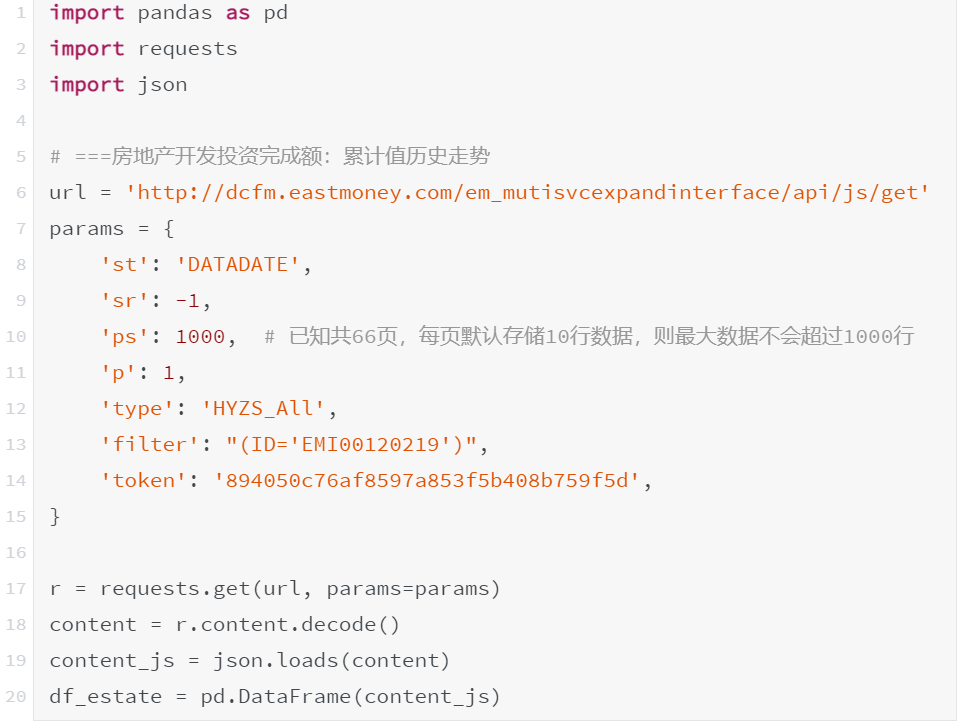
就这样,小编一共用了不到10行Python代码,就搞定了所需历史数据的网络爬虫。
爬虫复盘
在上述爬虫讲解过程中,我们不难发现,其实网络爬虫的一大部分工作都是在寻找「存储数据的网址」(即抓包),而其中需要代码实现的部分却并不复杂。只要掌握了抓包技巧,网络爬虫将会成为一件十分轻松的事情。
当然了,这并非代表爬虫就是一项简单的工作,在遇到较为复杂的网页,如微博、知乎等反爬较强、网页结构较为复杂、框架时常发生变动的网页,则需要其他技巧去解决网络爬虫任务。
但是,对于大部分网页来说,我们所面临的爬虫问题其实与本文中提及的案例并无太大区别,而本文也希望通过这一十分具有代表性的经典案例,为大家揭开爬虫的神秘面纱。




戳原文,直接购买「2021品职CFA课程」

👇👇👇





