


请问下hypothesis test的图为什么中间不是x bar ?
因为confidence interval就是x bar 在中间,然后hua画一个正太分布
而假设检验的时候,分母除以的是standard division of x bar, 我总是想着中间是x bar, 如果猜的数值落在尾巴上面就拒绝猜的数值,可是老师讲的是猜的数字在中间,有点混乱confidence interval 和hypo test图为啥不都是x bar在中间呢?



星星_品职助教 · 2020年01月01日
回复一下追问的问题,
首先解释一下“cap”。以置信区间为例,这里面要区分两个概念。一级的时候都是对“均值”做区间估计,所以都是“X bar”的形式。如果以95%正态分布为例,置信区间就是X bar加减1.96倍标准误。这里面X bar是对均值做的一个点估计(point estimate),而X bar±1.96倍标准误则是区间估计。
但在二级里,置信区间是通过OLS所得出的估计量为核心来计算的, 这个OLS得出的估计量就是b0 cap或者b1 cap等。由于不是求平均,这个时候就也不是“b1 bar”这种形式了。这时候置信区间是例如 b1 cap±1.96倍标准误的形式。
这里面的“b1 cap”就是point estimate的概念
----------------------------------------------------------------------------
可以关联一个知识点,由于OLS得出的估计量都是各种“cap”的形式,所以最后的线性方程就是:
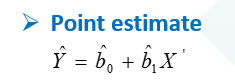
只要这个时候代入任意一个X的值,就可以得到一个Y的估计值,这个Y的估计值就是 Y cap,以上同时也是预测Y的过程。
----------------------------------------------------------------------------
然后说一下检验统计量。假设检验的第二步就是计算检验统计量,不同的检验的统计量算法不同。如果是t检验,算出来的就是t检验统计量(t-statistics)。同理,F检验就是F statistics,以此类推。
另外一个类似的概念就是临界值(critical value),有时候简写为tc,这个是查表查出来的,不需要计算。假设检验(以t检验为例)就是通过比较tc和t-statistics来判断是否拒绝原假设的。
星星_品职助教 · 2019年12月31日
同学你好,
我先简单讲一下概念,看看能否解决你的问题。
置信区间可以理解为X bar左右各多少倍的标准差所围成的一个“区间”,所以中心肯定是X bar。置信区间的主要应用是区间估计,也就是比如直接用170去估计全中国人的身高不靠谱,但是如果估计全中国人的身高有95%的可能在170的“左右”就靠谱多了,这个“左右”指的就是X bar左右各1.96倍标准差(假设正态分布)。
而假设检验的用处不同,假设检验可以理解为先估计了一个系数,然后检验这个系数估计的准不准。所以假设检验的核心是通过估计量算出来的一个检验统计量,然后和查表所得的一个临界值之间做比较。例如计算出来的t统计量是2.3,而临界值是1.96,这个时候检验统计量>临界值,就落在了拒绝域,所以拒绝原假设。这个过程和X bar是没有直接的关系的。
以上是从概念层面简单的辨析一下这两者的区别,如果里面有哪个细节还需要讲解就继续追问哈,加油
我叫仙人涨 · 2020年01月01日
通过估计量算出来的是x cap ,英文是叫做 estimate 是么? 检验统计量这个词是泛指所有的test算出来的数字,还是指t-statistic? 不好意思,中英文有点对不上哪个是哪个 谢谢!
星星_品职助教 · 2020年01月01日
字数较多,新起了一条回复哈