NO.PZ2023091601000107
问题如下:
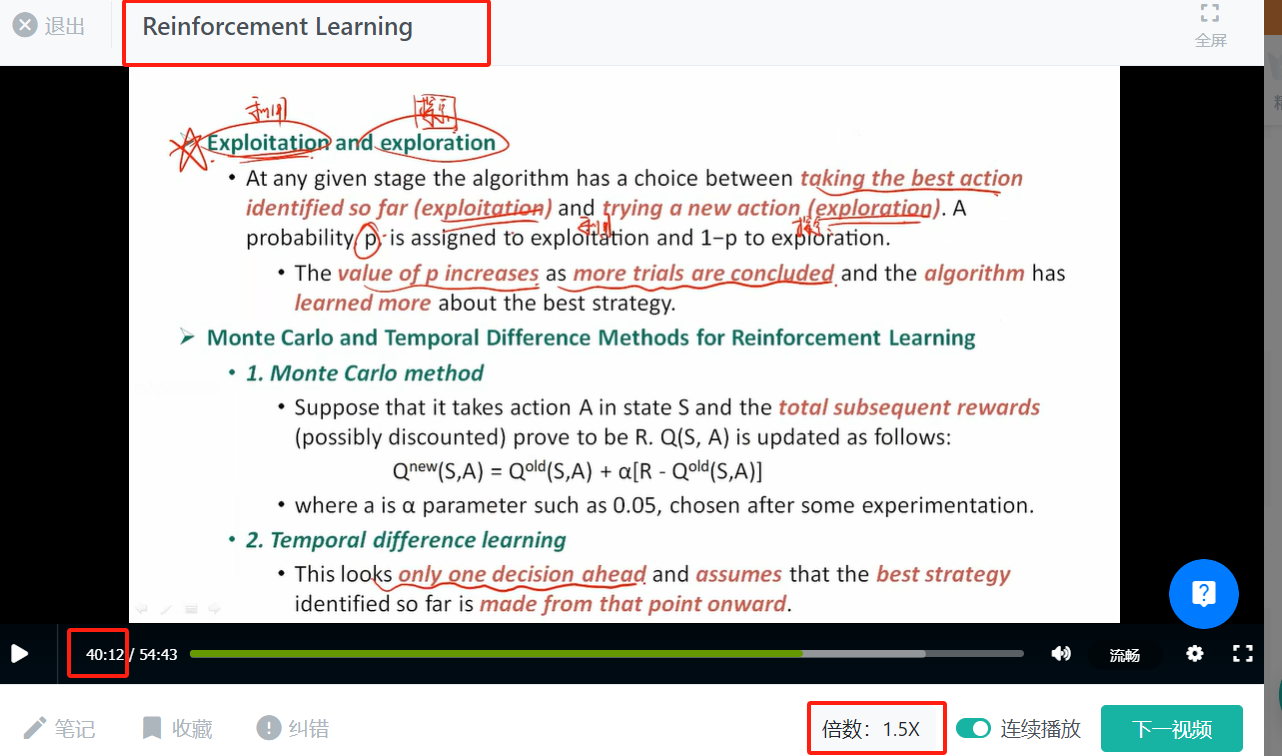
suppose that there are four states and three
actions, and that the current Q(S, A) values are as indicated in Table 14.2.

a. Suppose that on the next trial, Action 3 is
taken in State 4 and the total subsequent reward is 1.0. If α = 0.05, what will
the value of Q(4,3) be updated using Monte Carlo method ?
b. Suppose that the next decision
that has to be made on the trial we are considering turns out to be when we are
in State 3. Suppose further that a reward of 0.2 is earned between the two
decisions. Using the temporal difference method, we would note that the value
of being in State 3 is currently estimated to be 0.9. If a = 0.05, what will
the value of Q(4,3) be updated using Temporal difference learning?
解释:
a.If α = 0.05, the Monte Carlo method would lead to Q(4,3) being
updated from 0.8 to: 0.8 + 0.05(1.0 − 0.8) = 0.81
b. Suppose that when we take action A in state S we move to state S'.
We can use the current value for V(S’) to update as follows:
Qnew(S,A) = Qold(S,A) +α[R+γV(S') -
Qold(S,A)]
where R is the reward at the next step and γ
is the discount factor.
Thus, in this example, the temporal
difference method would lead to Q(4,3) being updated from 0.8 to: 0.8 +
0.05(0.2 + 0.9 − 0.8) = 0.815
公式是什么谢谢 什么考点