
相信学了那么久,大家都有点疲惫了,作为一个良心且持续提供干货的公众号,我们重启了闭着眼睛学FRM的栏目,去年有持续跟着学习的都说,有了我们这个栏目的加持,Current issues这部分有点虚幻的分数终于不用放弃过去了。
今年FRM二级的Current Issues部分一共有10篇热点文章,有3篇文章是沿用了去年的考纲,今天我们就来看看第一篇文章。

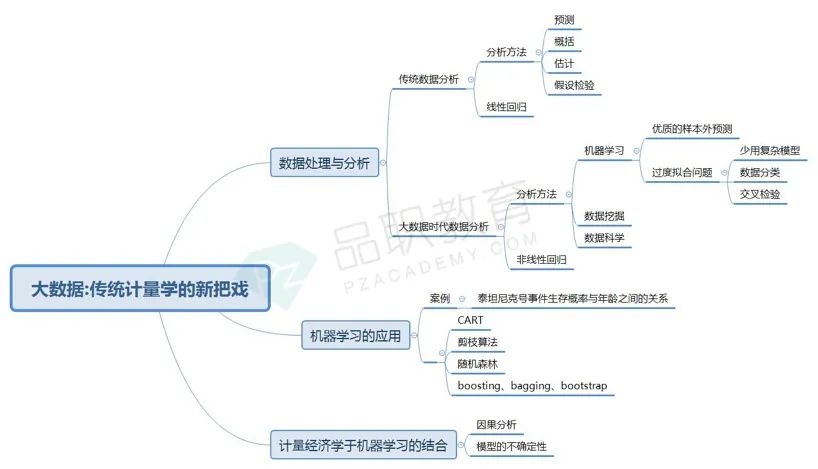
这篇论文的作者是被称为谷歌摇钱树的谷歌首席经济学家-范里安。文章中作者将大数据下的机器学习与传统计量分析相比较,认为在对于小数据进行分析时传统计量经济学表现很好,但随着分析大数据的需求日益凸显,传统的分析显得力不从心,这时就需要我们用到机器学习。

数据处理与分析
首先我们来看传统数据分析的基本原理,传统的数据分析是用样本代替总体进行分析得出结论用以预测。采用样本代替总体这种盲人摸象的做法虽不妥但受到在过去的数据分析中面临着数据量过小,无总体数据与计算能力有限两大难题的限制。
在大数据时代,数据将更加全面,计算能力也随着机器学习,人工智能等新技术的出现而有了本质的提升,我们可以在海量数据中更多的挖掘出更多隐含的复杂关系用以预测未来。
作者将传统数据分析分为四个主要维度:预测、概括、估计和假设检验。
对于大数据的处理一般采用的工具有:机器学习,数据挖掘,数据科学
![]() 机器学习:重点关注预测
机器学习:重点关注预测
![]() 数据挖掘:专注于数据的总结,寻找数据间的规律
数据挖掘:专注于数据的总结,寻找数据间的规律
![]() 数据科学:侧重预测和总结,同时也涉及到数据处理、可视化等。
数据科学:侧重预测和总结,同时也涉及到数据处理、可视化等。
机器学习预测数据的有两个主要的目标,一是在样本内建立的模型可以获得优质的样本外预测,还有就是解决过度拟合(overfitting problem)。过度拟合是在我们运用复杂模型时避免的问题。
文章中也简单探讨了几种可以解决过度拟合问题的方式,分别是
1.少用复杂模型
2.将数据按traning、testing、validation分类
3.交叉验证

机器学习的应用
对于机器学习的应用,作者介绍了分类和回归树(CART方法)。
在这个部分范里安用到了泰坦尼克的幸存者分析,将船上乘客按舱位和年龄分类然后分析其存活率。通过这个案例作者提出了一个观点,传统经济学主要是用于线性回归,对一些非线性关系无法做分析。如果只用传统经济经济学方法回归,得到的结论是人员的年龄因素对他们能否生存下来的影响是很低的。
但对于该事件有所了解或是看过电影的小伙伴都知道,在船体下沉时,船员是要求儿童优于成年人登上救生艇的,所以能否生存下来必然跟年龄存在一定的联系。在采用CART方法分析时就会发现年龄对于能否存活是一个很重要的影响因素。CART的结论明显是更符合现实的,从这个案例可知机器学习对于发掘复杂的非线性关系存在天然的优势。
CART方法:指先对数据进行分组让大样本变成small sample,再进行分析。
除了CART方法,作者还介绍了剪枝算法,随机森林以及一些其他的方法(Bootstrap,Bagging,Boosting),由于篇幅有限这里就不一一赘述了。
计量经济学与非传统学习的结合
最后,范里安认为计量经济学和机器学习在很多领域都有机会结合,比如计量经济学家已经在因果分析上取得了很多的成果,这可以用于促进机器学习的分析,解决机器学习纯预测的问题。再有就是讲到大数据时代我们更应该关注的是模型的不确定性,而非样本的不确定性。用多个小模型做平均会优于选择单一模型去做分析。
说到底,不论是传统数据分析还是新出现的机器学习,都是在历史数据中寻找规律用于未来的预测。因此我们说,big data 只不过是计量经济学的一个新把戏。
文中还会大家提供了很多的谷歌数据库,供大家参考使用:

话不多说,最后小编为大家奉上本篇文章的知识导图。
如果想要更多精彩内容,大家可以到喜马拉雅电台来听李老师的讲解哦,扫描下方的二维码即可直达!




配图来源网络


戳原文,直接购买「2020品职FRM课程」


